
Using TensorBoard in an Amazon SageMaker PyTorch Training job: a Step-by-Step Tutorial
Understanding the data flow of an Amazon SageMaker training job, and learning how to set up a TensorBoard on a SageMaker Pytorch training job by examples
TL;DR
In this article, we show you how to use TensorBoard in an Amazon SageMaker PyTorch training job in this blog. The steps are:
- Install TensorBoard at SageMaker training job runtime as here
- Configure tensorboard_output_config parameter when initializing PyTorch SageMaker estimator as here
- In PyTorch training script, log the data you want to monitor and visualize as here
- Startup tensorbard and point the log dir as the s3 location configured in step 2
Reason for This Blog
In one of my recent projects, I need to use TensorBoard to visualize metrics from a Amazon SageMaker PyTorch training jobs. After searching online and checking AWS official documents, SageMaker SDK examples and AWS blogs, I realize that there is no existing step-by-step tutorial for this topic. So, I write this article, and hopefully give you a ready-to-use solution.
How a SageMaker Training Job Exchanges Data between S3 and Training Instance
First, let us have a look the big picture when executing a PyTorch SageMaker training job. SageMaker facilities the process below:
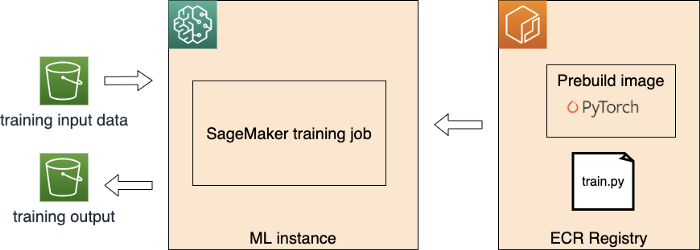
- Launch and prepare the requested ML instance(s)
- Download the input data from S3
- Pull the training image from ECR
- Execute the traing file (train.py in the figure above) as the entry point of training
- Push the training model artifact back to S3
Let us zoom in how data exchange between ML instance and S3 by the example below. Here we use SageMaker Python SDK.
estimator = PyTorch(entry_point='train.py',
output_path='s3://output-data-bucket/model/'
train_instance_count=1,
train_instance_type='ml.p2.xlarge',
)
estimator.fit(inputs={'training': 's3://input-data-bucket/train/',
'val': 's3://input-data-bucket/val/'})
Input data:
- input data location is configured by estimator.fit function inputs parameter. In this example, the train data is all objects with S3 prefix
s3://input-data-bucket/trainand same for the validation data. - Data is downloaded in ML instance and located in
/opt/ml/input/data/trainand/opt/ml/input/data/valfolder. “train” and “val” channel are configured by the key of the dictionary of estimator.fit.inputs parameter.
Output model artifact
- Your training script should write all your final model artifacts to the directory
/opt/ml/model. - SageMaker copies the data under
/opt/ml/modelas a single object in compressed tar.gz format to the S3 location you specified in the estimator object output_path parameter. In our example, the model artifact is located ass3://output-data-bucket/model/model.tar.gzafter the training job succeed.
Use TensorBoard in a SageMaker PyTorch Training Job Step-by-Step
Synchronize TensorBoard Log
SageMaker debugger is a feature introduced at the end of 2019. It provides a very easy way to emit TensorBoard data from a SageMaker training job. To enable the debugging hook to emit TensorBoard data, you need to specify the new option TensorBoardOutputConfig as follows:
from sagemaker.debugger import TensorBoardOutputConfig
tensorboard_output_config = TensorBoardOutputConfig(
s3_output_path='s3://path/for/tensorboard/data/emission',
container_local_output_path='/local/path/for/tensorboard/data/emission'
)
estimator = Pytorch(
role=role,
train_instance_count=1,
train_instance_type=train_instance_type,
tensorboard_output_config=tensorboard_output_config
)
During the training job, the debugging hook uploads the generated TensorBoard data in near real-time to an S3 path derived from the value of s3_output_path provided in the configuration.
In your training script, you should write your TensorBoard log into the local folder indicated by s3_output_pathin the ML instance. The default directory is /opt/ml/output/tensorboard/ if you skip the setup. Here is some example code:
import torch
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('/opt/ml/output/tensorboard/')
# in your training loop
for epoch in range(len(nr_epochs)):
# ...
writer.add_scalar('training loss', loss.item(), epoch)
Install TensorBoard in SageMaker PyTorch Container
TensorBoard package is not included in the SageMaker PyTorch containers by default, which is used by PyTorch estimator in SageMaker Python SDK. You have to install TensorBoard first. The easiest way is using the requirements.txt file described in the SDK document:
If there are other packages you want to use with your script, you can include a requirements.txt file in the same directory as your training script to install other dependencies at runtime. Both requirements.txt and your training script should be put in the same folder. You must specify this folder in source_dir argument when creating PyTorch estimator.
Startup TensorBoard Server
Now, we can startup TensorBoard server by the command F_CPP_MIN_LOG_LEVEL=3 AWS_REGION=YOUR-AWS-REGION tensorboard --logdir s3://tensorboard-output-location
- TensorBoard supports loading log files from S3 directly. We indicate the log directory as the one configured in TensorBoardOutputConfig.
- You need to setup AWS environment variable correctly, such as
AWS_ACCESS_KEY_IDandAWS_ACCESS_KEY_ID. F_CPP_MIN_LOG_LEVELcan suppress verbose logs- if you run the TensorBoard server in the SageMaker notebook instance, you can visit the TensorBoard page via presigned notebook instance url such as
https://YOUR-NOTEBOK-INSTANCE-NAME.notebook.YOUR-REGION.sagemaker.aws/proxy/6006/. It is noted that the last backslash is madantory, otherwise you will not see the TensorBoard page.